path = '../images/emoji_u1f98e.png'Experiment 1: Learning to Grow
Conducting the first experiment which involves training the cellular automaton to evolve from an initial seed to the desired shape
img_tensor = load_image(path)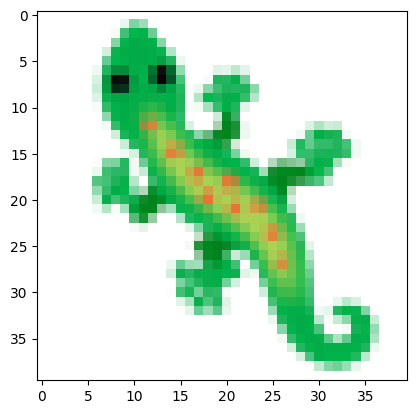
Create a starting seed
Create a grid of shape 1, 16, H, W initialized with zeros, where all elements are set to 0.
Place a single cell in the center of the grid. This central cell should have all channels (except for RGB) set to 1. The RGB channels of the seed cell are intentionally set to zero to ensure visibility on the white background.
seed.shapetorch.Size([1, 16, 40, 40])plt.imshow(seed[0, :4].detach().cpu().permute(1, 2, 0))
plt.show()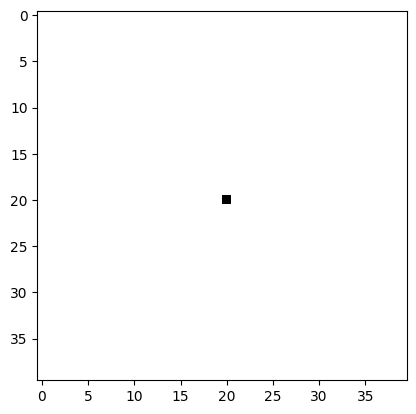
Training Loop
# training hyperparameters
n_epochs = 8000
batch_size = 8
lr = 2e-3
lr_gamma = 0.9999
betas = (0.5, 0.5)# initialize the model
ca = CAModel(CHANNEL_N).to(def_device)# optimization
import torch.optim as optim
optimizer = torch.optim.Adam(ca.parameters(), lr=lr, betas=betas)
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, lr_gamma)# create the input to the network and the target
model_in = seed.repeat(batch_size, 1, 1, 1)
target = img_tensor.repeat(batch_size, 1, 1, 1)for i in tqdm(range(n_epochs)):
optimizer.zero_grad()
steps = torch.randint(64, 96, (1,)).item()
res = ca(model_in, steps=steps)
loss = F.mse_loss(res[:, :4], target) # we only care about the RGBA channels
if i%500 == 0:
print(f"Epoch: {i} Loss: {loss.item()}")
loss.backward()
optimizer.step()
scheduler.step() 0%| | 1/8000 [00:00<1:39:26, 1.34it/s] 6%|██▌ | 503/8000 [00:34<08:02, 15.54it/s] 13%|████▉ | 1003/8000 [01:09<08:05, 14.42it/s] 19%|███████▎ | 1503/8000 [01:43<07:14, 14.96it/s] 25%|█████████▊ | 2003/8000 [02:18<07:01, 14.22it/s] 31%|████████████▏ | 2503/8000 [02:52<06:10, 14.84it/s] 38%|██████████████▋ | 3003/8000 [03:26<05:50, 14.26it/s] 44%|█████████████████ | 3503/8000 [04:01<05:11, 14.42it/s] 50%|███████████████████▌ | 4003/8000 [04:35<04:39, 14.31it/s] 56%|█████████████████████▉ | 4503/8000 [05:10<03:48, 15.28it/s] 63%|████████████████████████▍ | 5003/8000 [05:44<03:07, 16.01it/s] 69%|██████████████████████████▊ | 5503/8000 [06:18<02:55, 14.20it/s] 75%|█████████████████████████████▎ | 6003/8000 [06:52<02:13, 15.00it/s] 81%|███████████████████████████████▋ | 6503/8000 [07:26<01:43, 14.48it/s] 88%|██████████████████████████████████▏ | 7003/8000 [08:00<01:08, 14.51it/s] 94%|████████████████████████████████████▌ | 7503/8000 [08:35<00:33, 14.86it/s]100%|███████████████████████████████████████| 8000/8000 [09:08<00:00, 14.58it/s]Epoch: 0 Loss: 0.11318174749612808
Epoch: 500 Loss: 0.011708867736160755
Epoch: 1000 Loss: 0.008278374560177326
Epoch: 1500 Loss: 0.007219146471470594
Epoch: 2000 Loss: 0.006844399031251669
Epoch: 2500 Loss: 0.00406250637024641
Epoch: 3000 Loss: 0.0020757592283189297
Epoch: 3500 Loss: 0.0025464375503361225
Epoch: 4000 Loss: 0.004879282787442207
Epoch: 4500 Loss: 0.001170627772808075
Epoch: 5000 Loss: 0.0016236018855124712
Epoch: 5500 Loss: 0.0015115265268832445
Epoch: 6000 Loss: 0.0005236503202468157
Epoch: 6500 Loss: 0.0004948751884512603
Epoch: 7000 Loss: 0.0012785536237061024
Epoch: 7500 Loss: 0.0006189785781316459Test the training process of the network by generating and displaying an animation.
images = ca.grow_animation(seed, 200)
display_animation(images)As expected, after some time the automato is startig to lose the desired shape.